
| A Mandarin Speech
Synthesis System Combining HMM Spectrum Model, ANN
Prosody Model, and HNM Signal Model 結合 隱藏式馬可夫 頻譜模型, 類神經網路 韻律模型, 及HNM信號模型 之國語(華語)語音合成系統 |
|
| Hung-Yan Gu (古鴻炎),
Ming-Yen Lai (賴名彥), and Sung-Fung
Tsai (蔡松峰) e-mail: guhy@mail.ntust.edu.tw |
2010,
2013 |
| (a)
Support timbre transformation
(e.g. female => male) and changeable
speech-rate. (b) Support synchronous playing of a syllable-pronunciation symbol and its synthetic speech. (c) 375 (or 1,176) spoken sentences are used to train syllable or initial/final HMMs. (HMM training method: segmental k-means; for /pien/, the initial is /p/ and the final is /ien/) (d) Spectral parameters: 40 discrete cepstrum coefficients and their differentials per frame. (e) ANN prosody models are trained with 375 sentences. (f) Papers for reference: model combination(2010), f0 generation(2011), HNM signal synthesis(2009), timbre transformation(2012) Tt |
|
Synthetic
speech examples |
|
Program screen |
|
Recording of program execution |
|
Master Thesis Abstract |
| Synthetic
speech |
Example training utterances | ||
| Init. & Finl. HMM |
Syllable HMM |
||
|
|
using 1,176 sentences uttered by a male to train HMMs. |
, |
|
|
using only 375 sentences uttered by
the same male to train
HMMs. |
|
|
|
using 375 sentences uttered by female A to train HMMs. |
|
|
|
using 375 sentences uttered by female B to train HMMs. |
, |
|
using 801 sentences uttered by female B to train HMMs. |
||
| text content of Text A |
因為不知道你的名子, 就讓我叫你白花樹, 春天, 當你的花朵盛開時, 就像點亮了滿樹白蠟燭. 春天因你而閃閃發光, 笑臉因你而更加明媚, 微風因你而飄送芬芳, 日子就像緩緩的溪水. 白花樹變成了一幅畫, 引來了那麼多賞花人. 白花樹從此有了一個家, 他的根連著無數人的心. 名子也許並不那麼重要, 讓人懷念的名子最美好. |
||
| Synthetic
speech |
||
| Init. & Finl. HMM |
Syllable HMM |
|
| |
|
|
| |
|
using only 375 sentences uttered by the same male to train HMMs. |
|
|
using 375 sentences uttered by female A to train HMMs. |
|
|
using 375 sentences uttered by female B to train HMMs. |
|
using 801 sentences uttered by female B to train HMMs. |
|
| text content of Text B |
大清早, 公園裡的池塘, 是沒有皺紋的鏡子. 鏡子的一角, 映著打拳的太太, 鏡子的另一角, 映著讀報的老人, 鏡子的中間, 映著開白花的雲朵. 幾條姿態優雅的錦鯉, 游在不生皺紋的鏡子裡, 從打拳的身上, 游過去, 從讀報的紙上游過去, 從雲朵的花瓣上, 游過去. |
|
| Synthetic speech | ||
| Init.
& Finl. HMM |
Syllable HMM |
|
| |
|
|
|
|
using only 375 sentences uttered by the same male to train HMMs. |
| |
using 375 sentences uttered by female A to train HMMs. |
|
| |
|
using 375 sentences uttered by female B to train HMMs. |
| |
using 801 sentences uttered by female B to train HMMs. |
|
| text content of Text C |
天下雜誌民意調查顯示, 六成一的民眾擔心經濟傾中, 七成五的年輕人自認是台灣人. 天下雜誌昨天公布的最新民調指出, 高達六成一的民眾擔心台灣經濟過度依賴中國大陸. 天下民調的另一個數據也值得政府省思, 百分之六十二的受訪者認為自己是台灣人, 自認既是台灣人也是中國人的有百分之二十二, 自認是中國人的僅百分之八, 其中十八到二十九歲的年輕族群, 認為自己是台灣人的, 更高達百分之七十五, 是同類調查的新高. 天下雜誌對此, 引述亞太和平研究基金會董事長趙春山的解讀說, 以往選擇是中國人也是台灣人的比率最高, 牽涉的是對中華文化的認同及漢民族血濃於水的感情, 如今在國人的印象中, 談到中國代表的就是中華人民共和國, 因此更強化了台灣人對這片土地的認同感. |
|
Program
Screen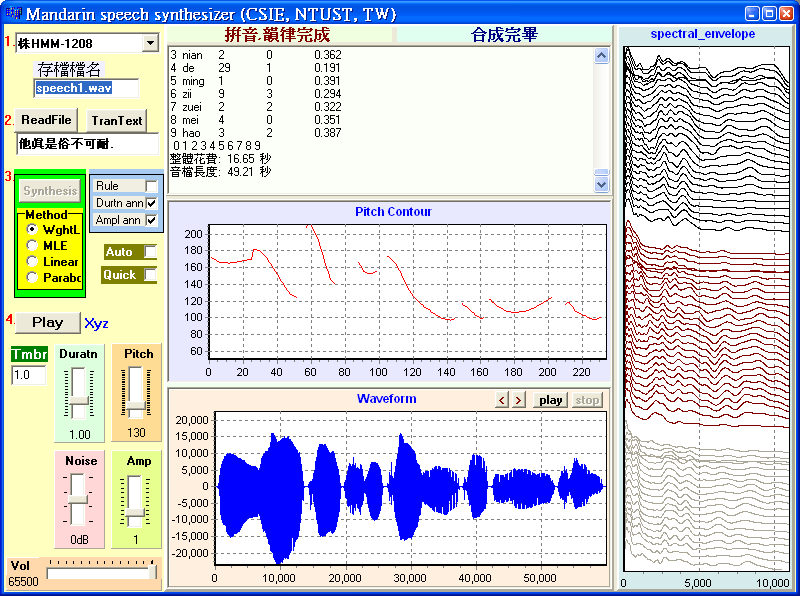 |
Recording
of Program Execution| 1)
male voice |
3)
timbre transformation |
|
 |
|
|
| 2) female voice | 4) changable speech-rate | |
|
faster: slower:
|
Master
Thesis Abstract of M. Y. Lai (2009)| title 題 目 |
A Mandarin Speech Synthesis System Combining HMM Spectrum Model and ANN Prosody Model 結合HMM頻譜模型與ANN韻律模型之國語語音合成系統 |
|||
| 摘 要 |
本
論文提出一種結合ANN韻律模型與HMM頻演模型的國語語音合成之架構。在訓練階段,對各個訓練語料音框算出DCC係數,以作為頻譜特徵參數,接著,對於
一種音節的多個發音,依DTW匹配出的頻演路徑作分群,各群建立一個HMM,並記錄各音節發音的文依性資訊。在合成階段,首先依據文依性資訊挑選出輸入文
句各音節的HMM模型,接著我們研究了一種HMM狀態無、有聲邊界之判定方法,然後使用音長ANN模型及狀態平均時長來決定HMM各狀態應該產生的音框
數。除了前人提出的MLE法,我們另外研究三種內插方法來產生各音框的DCC係數,以讓語音合成的速度達到即時處理。接著依據DCC係數轉出的頻譜包絡,
及另一個ANN產生出的基週軌跡,去控制HNM作語音信號的合成。聽測實驗的結果顯示,使用所提出的加權式線性內插法來產生DCC係數,合成出的語音信號
會比使用MLE法的,具有明顯較高的自然度;另外,使用ANN音長參數,也比使用HMM狀態本身的平均音長,會獲得明顯較高的自然度。 |
|||
| a b s t r a c t |
In
this thesis, a Mandarin speech synthesis system that combines HMM
spectrum model and ANN prosody model is proposed. In the training
phase, DCC (discrete cepstrum coefficients) are computed for each frame
of the training corpus and used as spectral parameters. For multiple
utterances of a same syllable, we first group them into a few clusters
according to their DTW (dynamic time warping) paths. Then, each cluster
is used to train an HMM (hidden Markov model). In addition, each
syllable utterance's HMM number and its contextual data is saved. In
the synthesis phase, for each syllable of an input sentence, an HMM of
the syllable is selected first according to this syllable's contextual
data. For a selected HMM, we have studied a way to split its states
into unvoiced and voiced ones. Then, we use duration ANN (artificial
neural network) and duration means of HMM states to decide how many
frames an HMM state should be assigned. Besides the MLE (maximum
likelihood estimate) method proposed by previous researchers, to
achieve the goal of real-time synthesis, we also study three more types
of interpolation methods to generate DCC coefficients for each frame.
Next, speech signal is synthesized by using the spectral envelope
derived from DCC coefficients and the pitch contour generated by
another ANN to control an HNM (harmonic plus noised model) based signal
synthesizer. The results of perception tests show that the speech
signal synthesized by the weighted linear interpolation method proposed
here is significantly natural than the speech signal synthesized by the
MLE method. In addition, the speech signal synthesized by using the
duration ANN is also significantly natural than the speech signal
synthesized by using the duration means of HMM states. |
|||
| 賴名彥合成的音檔 Speech files synthesized by M. Y. Lai (2009) |
|
Training
Sentences| 375
sentences |
801
sentences |